
¿Qué es un archivo?
Podríamos definir de forma genérica el termino archivo como un conjunto de datos con un nombre asociado.
Debido a su relación con el conjunto de funciones conocidas como llamadas al sistema o system calls se puede entender un archivo como una extensión del conjunto de datos asociados a un proceso, sin embargo el hecho de que estos datos continúen existiendo aun que el proceso haya terminado, los hace especialmente útiles para el almacenamiento de información a largo plazo.
Los archivos suelen residir en dispositivos de almacenamiento secundario, como discos rígidos, cintas (¿aun se utilizan las cintas?), o USB.
Algunos sistemas operativos imponen a todos sus archivos una estructura determinada bien definida. En Linux un archivo no es más que una secuencia de bytes (8 bits).
¿Qué es un sistema de archivos?
Un sistema de archivos es aquella parte del sistema responsable de la administración de los datos en los dispositivos de almacenamiento secundario.
El sistema de archivos debe proporcionar los medios necesarios para un almacenamiento seguro y privado de la información y, a la vez, la posibilidad de compartir esa información en el caso de que el usuario lo desee.
Entre las características más relevantes del sistema de archivos de Linux podemos mencionar las siguientes:
- Los usuarios tienen la posibilidad de crear, modificar y borrar los archivos y directorios.
- Cada archivo tiene definidos tres tipos de acceso diferentes: Acceso de lectura [r], acceso de escritura [w] y acceso de ejecución [x]
- A su vez, esos tres tipos de acceso pueden extenderse a la persona propietaria del archivo, al grupo al cual está adscrita dicha persona y al resto de los usuarios del sistema. Esto permite que los archivos puedan ser compartidos de forma controlada.
- Cada usuario puede estructurar sus archivos como desee, el núcleo de Linux no impone ninguna restricción.
- Proporciona la posibilidad de cifrado y descifrado de la información. Eso se puede hacer para que los datos sólo sean útiles (legibles) para las personas que conozcan la clave de descifrado.
- El usuario tiene una visión lógica de los datos, es el sistema encargado de manipular correctamente los dispositivos y darle soporte físico deseado a la información. El usuario no tiene que preocuparse por los dispositivos físicos, es el sistema el que se encarga de la forma en que se almacenan los datos desde y hacia los mismos.
Linux y la estructura de árbol invertido
En Linux los archivos están organizados en lo que se conoce como directorios. Un directorio no es más que un archivo algo especial, el cual contiene información que permite localizar otros archivos. Los directorios pueden contener, a su vez, nuevos directorios, los cuales se denominan subdirectorios. A la estructura resultante de esta organización se la conoce con el nombre de estructura en árbol invertido.
En él, todos los archivos y directorios dependen de un único directorio denominado directorio raíz o root, el cual se representa por el símbolo slash “/”. En el caso de que tengamos varios dispositivos físicos de almacenamiento secundario en el sistema, (normalmente discos o particiones de discos), todos deben depender del directorio raíz, como un subdirectorio que depende, directa o indirectamente de la raíz. A esta operación se la conoce con el nombre de montaje de un subsistema de archivos.
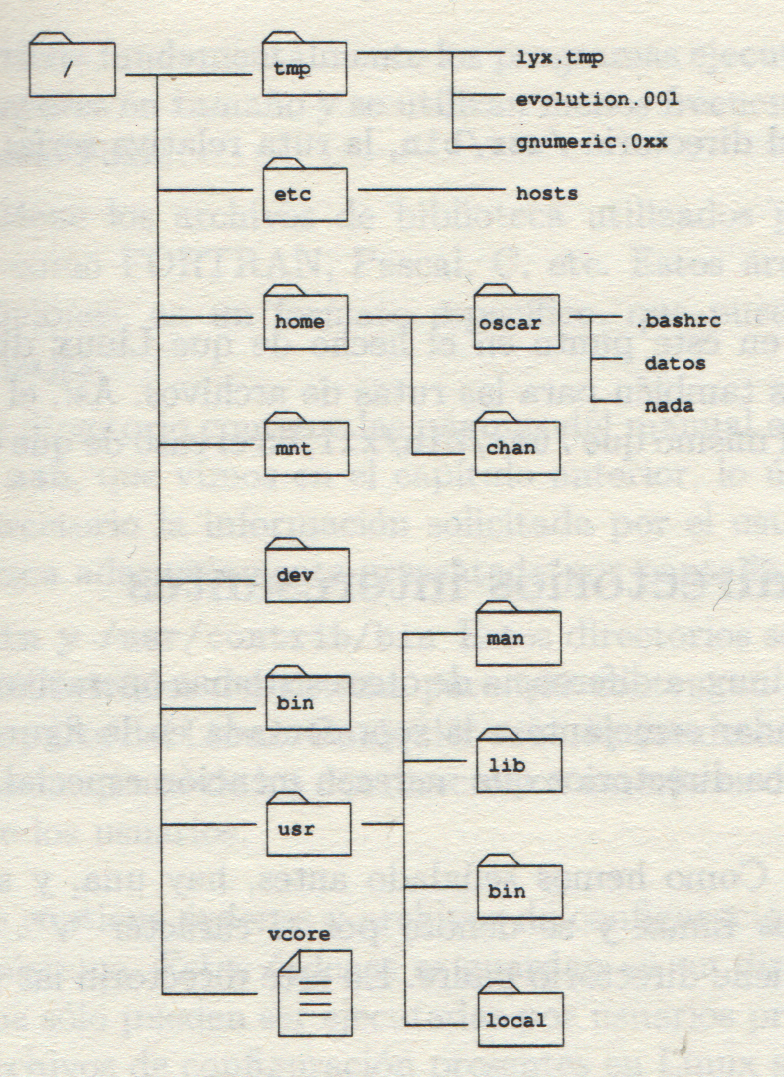
Los archivos se identifican en la estructura de directorios por lo que se conoce como pathname o camino. Así, la cadena /etc/passwd identifica a passwd como un elemento que cuelga del directorio etc el cual a su vez cuelga del directorio raíz. (/). A partir de la cadena /etc/passwd no podemos saber si passwd es un archivo o directorio. Cuando el nombre del camino empieza con el carácter / se dice que el camino es absoluto. Linux también dispone de nombres de camino relativos, por ejemplo, si nuestro directorio actual es /usr, la cadena bin/troff identifica al archivo o directorio /usr/bin/troff. A esta cadena se la conoce, como camino relativo puesto que no comienza con el símbolo slash.
Los subdirectorios “.” y “..”
Cuando creamos un directorio se crean automáticamente dos subdirectorios cuyos nombres son “.” (punto) y “..” (punto punto).
“.” es una entrada en el directorio que identifica al directorio mismo y “..” es una entrada en el directorio padre, es decir, aquel directorio del cual cuelga el subdirectorio actual. Las cadenas “.” y “..” también pueden ser utilizadas en el nombre de un camino relativo.
Por ejemplo: Si consideramos el archivo xterm, éste puede ser referenciado tanto por su ruta absoluta como por la relativa. La ruta absoluta es algo que no depende de nuestra posición actual y es de la forma:
** /usr/bin/X11/xterm **
La ruta relativa depende del directorio en que nos encontremos en cada instante. Por ejemplo, si estuviéramos colocados en el directorio ** /usr/lib , la ruta relativa de **xterm sería:
../bin/X11/xterm
Si estuviesemos en el directorio /usr/bin, la ruta relativa sería:
X11/xterm
En Linux si hay diferencia entre letras mayúsculas y minúsculas tambien para las rutas de archivos. Asi, el directorio cuya ruta es /usr/bin/X11 no es lo mismo que /usr/bin/x11, en el caso de que este último existiera.
